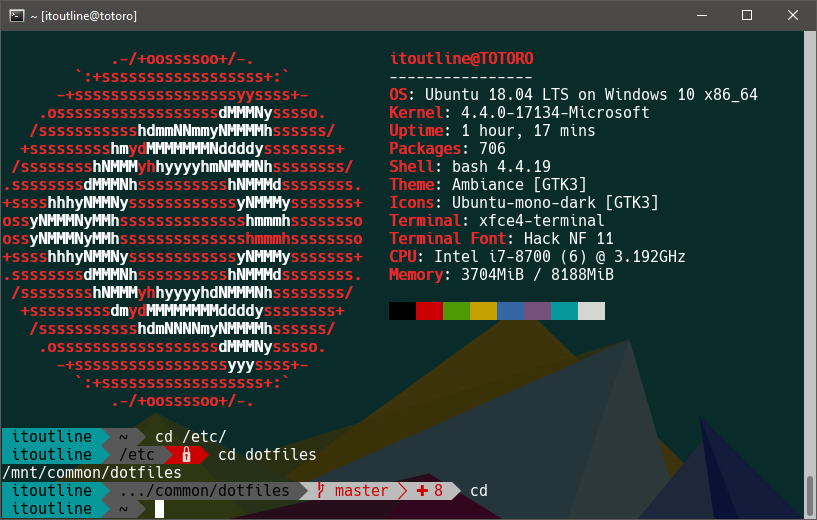
Ubuntu 18.04 ma nowszą wersję xfce4-terminal 0.8.7.3 i jest w niej poprawiony pewien szczegół który mnie irytował, przypadkowe przechodzenie w tryb zaznaczania przy kliknięciu na okno xfce4. Bardzo łatwo było to zrobić i jeśli akurat miało się coś w schowku to trzeba było ponownie do niego kopiować. Teraz jest normalnie a na dodatek zaznaczenie blokowe w terminalu z wciśniętym Shift i Ctrl działa świetnie.
Została też poprawiona obsługa zmiennej TERM i COLORTERM, teraz sam xfce4 ustawia je bez konieczności dosyć złej praktyki modyfikowania ich w .bashrc itp.:
12
TERM=xterm-256color
COLORTERM=truecolor
Testowałem różne rozwiązania terminalowe na Windows - mintty, putty (via server ssh), Hyper, cmder), chyba tylko xfce4-terminal jest teraz bardzo bliski tego czego bym oczekiwał po terminalu (nawet mimo tego, że trzeba go uruchamiać przez Server X). Jest prawie tak dobry jak iTerm2 na OSX ;)
Kilka lat temu pozbyłem się z domu “blaszaka”. Nie gram, w związku z czym w miarę wydajny laptop miał mi spokojnie wystarczyć. No i w sumie tak było, brakowało mi tylko jednej rzeczy, jakiegoś wspólnego domowego zasobu sieciowego. Nie było to jakoś krytyczne, podejmowałem próby z BananaPi wyposażonym w port sata (bardzo słabo), podpinałem dysk do posiadanych routerów po USB3 (niewiele lepiej) a na dodatek ciągle miałem w głowie, że jeśli mi ten dysk padnie to tracę wszystko w związku z czym jakichś krytycznych rzeczy tam nie trzymałem.
W końcu zdecydowałem się jakoś docelowo rozwiązać problem i wybór padł na NAS Asus 6202T. Rozwiązanie sprawdzało się całkiem dobrze ale pojawiła się potrzeba “upchnięcia” trochę większej ilości wirtualnych maszyn, wersja Docker-a była nie tą, której potrzebowałem, brak wsparcia dla osobnych dysków SSD (w tamtym czasie) i jakieś inne drobne rzeczy skłoniły mnie do poszukania czegoś innego.
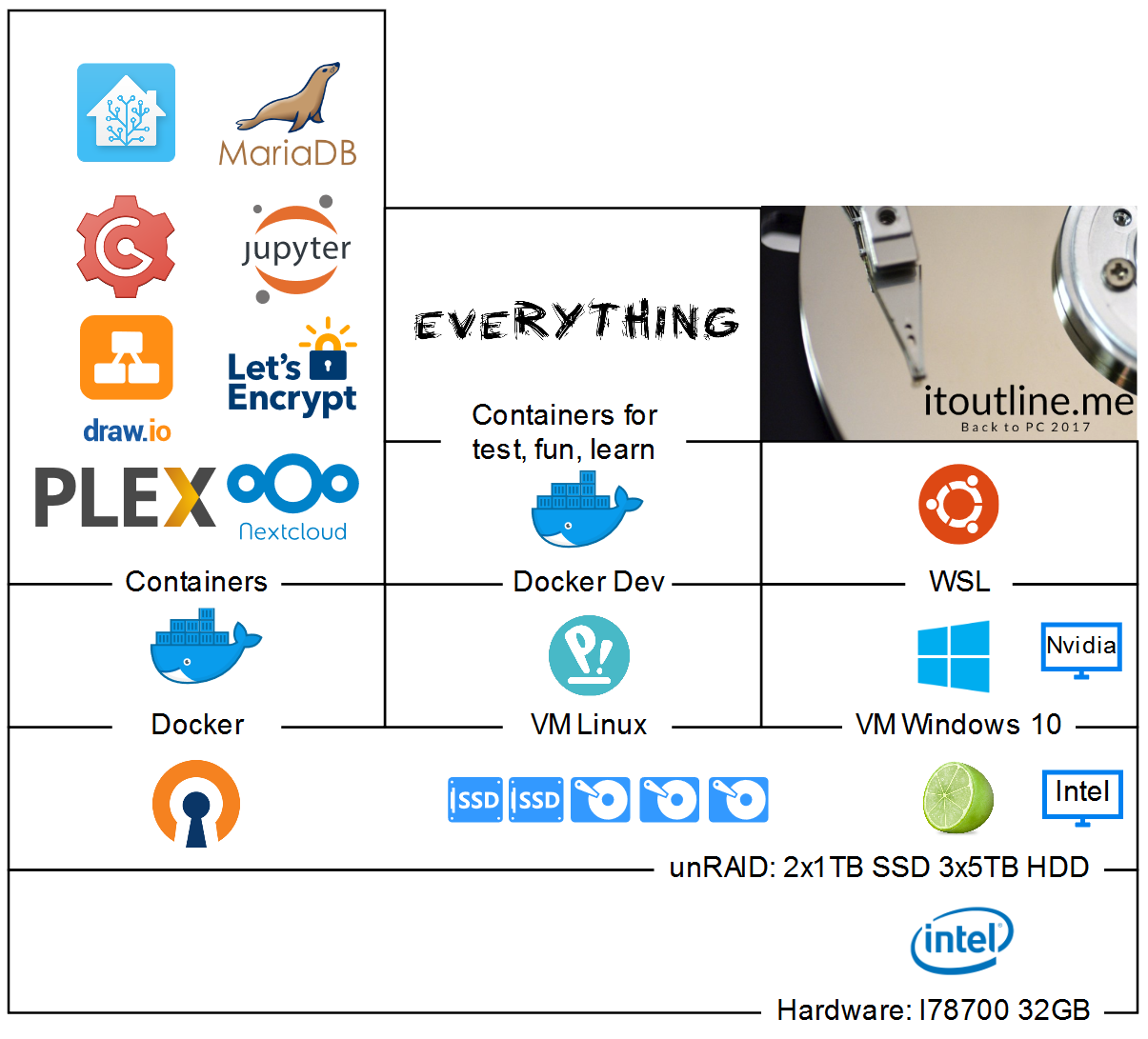
No i trafiłem na Unraid-a. Jest to dedykowany pod storage OS oparty na Linuxie. Podstawowe zalety w mojej ocenie:
Wsparcie dla wirtualizacji/dokeryzacji.
Obsługa SSD przez tzw. “cache pool”.
Bardzo łatwe dodawanie nowych docker-ów.
Niezależność od dostawcy sprzętu, to chyba największy plus, kupuje komponenty dokładnie take jakich potrzebuje. (Ludzie preferujący rozwiązania “półkowe” niekoniecznie uznają to za zaletę).
Możliwość “podpięcia” karty graficznej bezpośrednio do VM, dzięki czemu nie ma różnicy pomiędzy pracą na maszynie fizycznej a VM.
Całość ruchu sieciowego pomiędzy wszystkimi hostami odbywa się w obrębie jednej fizycznej maszyny:
Duża frajda z posiadania własnej chmury, Plex + NextCloud + Collabora + draw.io (Collabora - pakiet biurowy, może odstaje nieco jakością od rozwiązań gigantów ale już z draw.io korzysta mi się lepiej niż z Visio).
Wszytko jest na dyskach w RAID (co nie zwalnia z backup-ów ale zdecydowanie jest raźniej ;)
Wady:
Większe zużycie energii 50W, w przypadku Asus-a 10W (wartości mocno uśrednione). Coś za coś, I7 8700 vs Celeron
Rozwiązanie nie jest darmowe.
Nadal mam problem z podłączeniem zintegrowanej grafiki do VM Linuxowej (grubsza sprawa, musi dojść do przełączenia systemu obsługującego IGD z unRAID na VM).
Całość wygląda tak:
Historia zatoczyła koło, teraz potrzebuje byle jakiego laptopa i mogę pracować na VM zdalnie (w czym na pewno pomaga 50Mb upstream-u od dostawcy Internetu). Co najważniejsze, całość działa zaskakująco stabilnie. Niesamowite jak wiele funkcji może spełniać dzisiaj PC w domu (cztery ostatnie to VM) a wszystko to dzięki wirtualizacji i konteneryzacji.
Obciążenie CPU w tym czasie (żadna z maszyn nie robiła nic szczególnego, na Windows 10, Firefox z 20+ zakładkami i kilka pomniejszych programów):
Kiedyś bardzo optowałem za stawianiem drobnych rzeczy jak np. Home Assistant na RPI czy podobnych ale teraz wydaje mi się, że takie “pudło” jest zdecydowanie lepszym rozwiązaniem, ogarnia wszystko :)
Świetne projekty elektroniczne DIY - Boldport Club, zapisałem się i zacząłem od klona Arduino The Cuttle. Nie był to cały kit tylko sama płytka i trochę nieudana, bo od spodu jest miejscami farba na padach do lutowania. Mimo wszystko działa :)
$ ./picocom.exe -b 115200 /dev/ttyS3
picocom v2.3a
port is : /dev/ttyS3
flowcontrol : none
baudrate is : 115200
parity is : none
databits are : 8
stopbits are : 1
escape is : C-a
local echo is : no
noinit is : no
noreset is : no
nolock is : no
send_cmd is : sz -vv
receive_cmd is : rz -vv -E
imap is :
omap is :
emap is : crcrlf,delbs,
logfile is : none
Type [C-a] [C-h] to see available commands
Terminal ready
HiZ>
HiZ>
W przypadku posiadania serwera w sieci Internet zawsze najlepiej jest ograniczać do niego dostęp tylko do tego co rzeczywiście chcemy, żeby było na nim dostępne. Dodatkowo ograniczenie do konkretnych klas czy adresów w przypadku dostępu do interfejsów umożliwiających większą kontrolę nad serwerem jest także dobrą praktyką (jeszcze lepszą jest nie eksponowanie ich w Internecie w ogóle;)
Ostatnio prowadziłem testy na takim serwerze i naturalnym było np. ograniczenie dostępu do SSH dla konkretnych adresów. Problem polega na tym, że o ile w firmie miałem statyczny adres to w domu już nie. Mogłem ustawić regułę na obecny domowy adres ale za kilka godzin mogła być już nieaktualna. Wyjściem z sytuacji okazał się, jak bardzo często się zdarza, prosty skrypt i dyndns.
Wchodzenie na stronę unblock.us i aktualizowanie bieżącego adresu IP zaczęło mnie naprawdę męczyć. Na szczęście można tego uniknąć dosyć prosto. Wystarczy prosty skrypt na routerze (czy dowolnym serwerze linuxowym jaki mamy w domu, chyba każdy ma coś na poziomie minimum rpi w dzisiejszych czasach ;), który będzie sprawdzał co jakiś czas adres zewnętrzny i aktualizował go w unblock.us.
update_unblock.sh
123456789101112131415161718192021222324252627
#!/usr/bin/env bash# --==itoutline.me==--SCRIPT_NAME="$(basename $0)"IP_ADDR=/tmp/active_ip_addr
IP_STATUS=/tmp/ip_update_status
CURRENT_IP=$(dig +short myip.opendns.com @resolver1.opendns.com)function update_ip { curl -s -o $IP_STATUS"https://api.unblock-us.com/login?adres_email:hasło" logger "[$SCRIPT_NAME]: IP updated: $CURRENT_IP; Response: $(cat $IP_STATUS)"echo$CURRENT_IP > $IP_ADDR}if[["$CURRENT_IP"=~ ^[0-9]{2,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]];thenif[ ! -f $IP_ADDR];then update_ip
elseOLD_IP=$(cat $IP_ADDR)if[["$CURRENT_IP" !="$OLD_IP"]];then update_ip
fifielse logger "[$SCRIPT_NAME]: Network error or incorrect answer from the IP provider"fi
W miejscach adres_email i hasło trzeba podać swoje dane oraz dorzucić skrypt do crona.
*/2 * * * * /root/update_unblock.sh 2>&1 |logger
Skrypt będzie się wykonywał co dwie minuty.
Skrypt można również wykorzystać do innych serwisów, w przypadku darmowego tvunblock.com polecenie curl z funkcji update_ip należałoby zastąpić:
Zastąpienie odpytywania zewnętrznego serwisu o publiczny adres IP
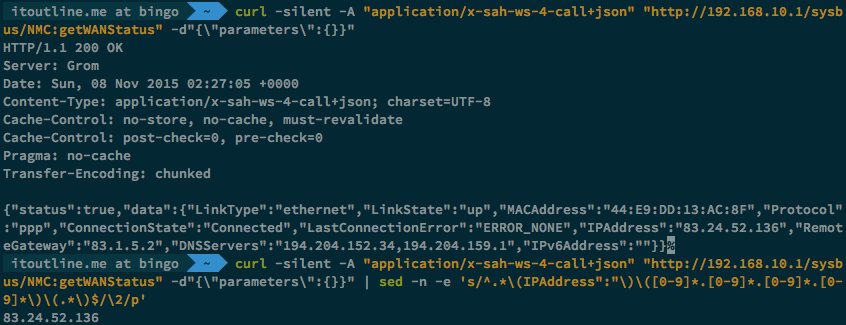
Serwisów dostarczających za pomocą jakiegoś web api zewnętrzny adres ip jest dużo ale nie zawsze trzeba z nich korzystać. Jeśli router/modem pozwala na pobieranie z niego informacji o adresie WAN, dlaczego tego nie użyć? W przypadku Liveboxa/Funboxa zmienną CURRENT_IP można ustawić w ten sposób:
CURRENT_IP=$(curl -silent -A "application/x-sah-ws-4-call+json" "http://192.168.1.1/sysbus/NMC:getWANStatus" -d"{\"parameters\":{}}" | sed -n -e 's/^.*\(IPAddress":"\)\([0-9]*.[0-9]*.[0-9]*.[0-9]*\)\(.*\)$/\2/p')
W praktyce (jak widać nie tylko adres ip portu WAN można podejrzeć):
Crontab tuning
Rozwiązania, które opierają się na crontabie i czesto są uruchamiane zaśmiecają sysloga:
Nov 8 16:49:01 bananapi /USR/SBIN/CRON[27209]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Nov 8 16:51:01 bananapi /USR/SBIN/CRON[27221]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Nov 8 16:53:01 bananapi /USR/SBIN/CRON[27233]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Nov 8 16:55:01 bananapi /USR/SBIN/CRON[27244]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Nov 8 16:57:01 bananapi /USR/SBIN/CRON[27255]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Nov 8 16:59:01 bananapi /USR/SBIN/CRON[27266]: (root) CMD (/root/update_unblock.sh 2>&1 |logger)
Dlatego kiedy już wiadomo, że skrypt działa poprawnie można pokusić się o wyłączenie logowania crona. Na Debianie to modyfikacja pliku /etc/rsyslog.conf:
rsyslog.conf
123456789101112131415
################### RULES ##################### First some standard log files. Log by facility.#auth,authpriv.* -/var/log/auth.log
*.*;auth,authpriv.none,cron.none -/var/log/syslog
#cron.* -/var/log/cron.logdaemon.* -/var/log/daemon.log
kern.* -/var/log/kern.log
lpr.* -/var/log/lpr.log
mail.* -/var/log/mail.log
user.* -/var/log/user.log
Dorzucenie cron.none i restart usługi sudo /etc/init.d/rsyslog restart wyciszy crontaba. Można również przekierować logi do osobnego pliku cron.log ale szkoda karty SD. Od tej pory syslog nie jest floodowany z powodu skryptu i mamy tylko informacje kiedy faktcznie skrypt wykona jakąś pracę:
Nov 8 20:16:02 bananapi logger: [update_unblock.sh]: IP updated: 178.42.100.100; Response: active
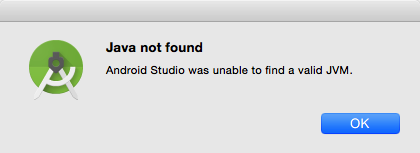
Definiowanie zmiennych systemowych w OSX jest takie sobie… Nie mówię tutaj o zmiennych, które można ustawić w plikach inicjalizacyjnych powłoki shellowej (bash, zsh, fish czy co komu odpowiada). Tam akurat wszystko jest całkiem prosto ale o ustawieniu zmiennej bez uruchamiania terminala po starcie systemu. Natrafiłem na potrzebę zdefiniowania takiej zmiennej przy zabawie z Android Studio. Po zainstalowaniu Javy i wspomnianego oprogramowania, próba jego uruchomienia kończyła się tak:
Problemem okazał się brak zmiennej STUDIO_JDK. Można ten problem obejść np. tak:
launchctl setenv STUDIO_JDK /Library/Java/JavaVirtualMachines/jdk1.8.0_25.jdk
open /Applications/Android\ Studio.app
Tylko, że jakoś konieczność uruchomienia terminala po to, żeby pracować w aplikacji graficznej do mnie nie przemawia. Udało mi się znaleźć ciekawe rozwiązanie problemu tutaj.
Zmienne systemowe
Zmienne mogą być ustawione na poziomie użytkownika (ustawienie wywoływane przez /Library/LaunchAgents/environment.user.plist) lub root-a (/Library/LaunchDaemons/environment.plist). Rozwiązanie zakłada jeden plik w którym będą definiowane zmienne /etc/environment, co jest bardzo ok bo nie przypominam sobie, żebym kiedyś potrzebował różnych. Kolejnym plusem jest fakt, że modyfikacja /etc/environment czyli dodanie jakiejś zmiennej automatycznie jest zaczytywane i dostajemy wzrokową informację w postaci chwilowego zniknięcia Dock-a.
Jedyny minus ale to jest raczej nie do obejścia to fakt, że już działająca aplikacja nie pobierze informacji o nowej zmiennej, musi być ponownie otworzona.
Zmienna PATH
To rozwiązanie jest jeszcze lepsze i dopóki będzie działało na OSX to będę z niego korzystał a mianowicie zmiany dokonujemy w pliku /etc/paths. To zwykły plik tekstowy w którym możemy dodawać kolejne linijki z wymaganymi przez nas ścieżkami. Po ponownym uruchomieniu terminala dopisana przez nas ścieżka znajdzie się w zmiennej PATH.
Ostatecznie
Przygotowałem skrypt bashowy, który tworze niezbędne pliki i ustawia ich parametry.
Od tej pory zdefiniowanie jakiejkolwiek zmiennej, która będzie zawsze i wszędzie widoczna to umieszczenie jej w /etc/environment.
Pożyteczne komendy
Ustawienie zmiennej z poziomu terminala (będzie od razu widoczne w systemie ale na liście zmiennych wyświetlanej np. za pomocą env czy echo $STUDIO_JDK pojawi się dopiero po restarcie terminala:
W końcu wróciłem na stare śmieci, działam na OSX Yosemite. Przyznam, że zaskakują mnie oceny tej wersji OSX na AppStore ponieważ póki co jedyny kłopot jakiego ja doświadczyłem to ten z tytułu wpisu. Ponad tydzień spędzony na konfigurowaniu, instalowaniu, modyfikowaniu nie przyniósł jakichś większych zgrzytów, no ale pożyjemy zobaczymy. Zdecydowanie za wcześnie na wyciąganie wniosków.
Na pewno beznadziejnie działa przewijanie za pomocą dwóch palców w Chromie, bardzo często zdarzało mi się podczas przewijania strony w górę/dół lądować na poprzednio przeglądanej. Wydaje mi się, że to bardziej wina przeglądarki niż systemu…
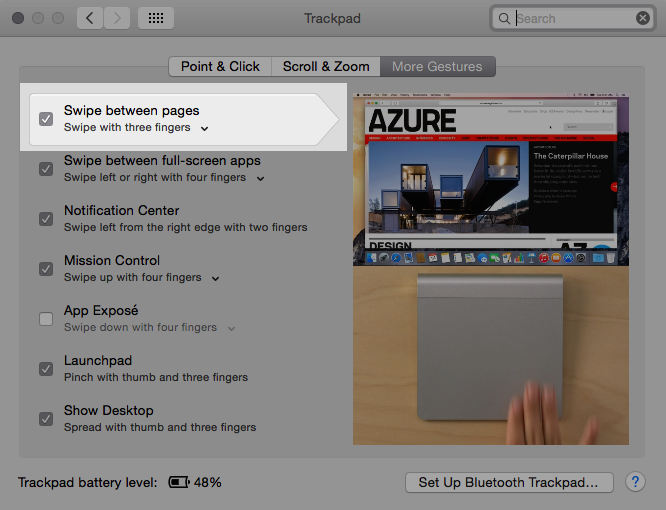
Rozwiązanie problemu to wyłączenie przewijania w Chromie:
Jeśli chcemy można w konfiguracji Touchpad-a zastosować poniższe ustawienia, dzięki czemu przechodzenie pomiędzy stronami przestanie być losowe. Jedyny minus to, że musimy użyć trzech palców.
Tak się nieszczęśliwie poukładało w moim życiu, że na jakiś czas wylądowałem z windowsowym laptopem. Zawsze kiedy musiałem korzystać z systemu MS instalowałem od razu Cygwina. Niestety czasami nie była to “bułka z masłem”, często coś tam nie do końca działało albo były problemy z samą instalacją. Zdarzało się, że trochę pracy było potrzebne ale i tak świetnie, że komuś się chciało i Cygwin w ogóle powstał. Teraz jest jeszcze lepiej bo powstało coś dającego Cygwina w bardzo fajnym opakowaniu. Mowa o Babun.
Instalacja
Sprowadza się do pobrania archiwum, rozpakowania i uruchomieniu skryptu. Standardowo instaluje się w katalogu domowym jako .babun.
Pierwsze wrażenia
Na pulpicie tworzy się skrót, który uruchamia terminal mintty a tam od razu mamy skonfigurowane zsh i jest git. Instalacja/deinstalacja pakietów za pomocą pact install oraz pact remove jest dużym plusem. Usunięcie Babun-a to skasowania jego katalogu, uwielbiam tego typu programy :)
Serwer SSH
Serwer SSH na Windowsie to chyba nigdy nie było proste. Tutaj też nie działa bez drobnych modyfikacji ale nie jest najgorzej. No i trzeba przyznać, że w Windows 8.1 dodawanie i usuwanie serwisów nawet z poziomu Babuna/Cygwina nie wymaga restartu. Miłe zaskoczenie.
Zaczynamy od uruchomienia Babuna jako Administrator i wydajemy następujące komendy:
ssh-keygen: generating new host keys: RSA1 RSA DSA ECDSA ED25519
*** Info: Creating default /etc/ssh_config file
*** Info: Creating default /etc/sshd_config file
*** Info: Privilege separation is set to yes by default since OpenSSH 3.3.
*** Info: However, this requires a non-privileged account called 'sshd'.
*** Info: For more info on privilege separation read /usr/share/doc/openssh/README.privsep.
*** Query: Should privilege separation be used? (yes/no) yes
*** Info: Note that creating a new user requires that the current account have
*** Info: Administrator privileges. Should this script attempt to create a
*** Query: new local account 'sshd'? (yes/no) yes
*** Info: Updating /etc/sshd_config file
*** Query: Do you want to install sshd as a service?
*** Query: (Say "no" if it is already installed as a service) (yes/no) yes
*** Query: Enter the value of CYGWIN for the daemon: [] ntsec
*** Info: On Windows Server 2003, Windows Vista, and above, the
*** Info: SYSTEM account cannot setuid to other users -- a capability
*** Info: sshd requires. You need to have or to create a privileged
*** Info: account. This script will help you do so.
*** Info: You appear to be running Windows XP 64bit, Windows 2003 Server,
*** Info: or later. On these systems, it's not possible to use the LocalSystem
*** Info: account for services that can change the user id without an
*** Info: explicit password (such as passwordless logins [e.g. public key
*** Info: authentication] via sshd).
*** Info: If you want to enable that functionality, it's required to create
*** Info: a new account with special privileges (unless a similar account
*** Info: already exists). This account is then used to run these special
*** Info: servers.
*** Info: Note that creating a new user requires that the current account
*** Info: have Administrator privileges itself.
*** Info: No privileged account could be found.
*** Info: This script plans to use 'cyg_server'.
*** Info: 'cyg_server' will only be used by registered services.
*** Query: Do you want to use a different name? (yes/no) no
*** Query: Create new privileged user account 'cyg_server'? (yes/no) yes
*** Info: Please enter a password for new user cyg_server. Please be sure
*** Info: that this password matches the password rules given on your system.
*** Info: Entering no password will exit the configuration.
*** Query: Please enter the password:
*** Query: Reenter:
*** Info: User 'cyg_server' has been created with password 'dynamic1'.
*** Info: If you change the password, please remember also to change the
*** Info: password for the installed services which use (or will soon use)
*** Info: the 'cyg_server' account.
*** Info: Also keep in mind that the user 'cyg_server' needs read permissions
*** Info: on all users' relevant files for the services running as 'cyg_server'.
*** Info: In particular, for the sshd server all users' .ssh/authorized_keys
*** Info: files must have appropriate permissions to allow public key
*** Info: authentication. (Re-)running ssh-user-config for each user will set
*** Info: these permissions correctly. [Similar restrictions apply, for
*** Info: instance, for .rhosts files if the rshd server is running, etc].
*** Info: The sshd service has been installed under the 'cyg_server'
*** Info: account. To start the service now, call `net start sshd' or
*** Info: `cygrunsrv -S sshd'. Otherwise, it will start automatically
*** Info: after the next reboot.
*** Info: Host configuration finished. Have fun!
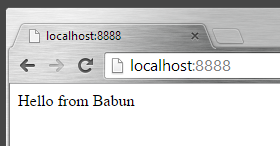
importtornado.ioloopimporttornado.webclassMainHandler(tornado.web.RequestHandler):defget(self):self.write("Hello from Babun")application=tornado.web.Application([(r"/",MainHandler),])if__name__=="__main__":application.listen(8888)tornado.ioloop.IOLoop.instance().start()
Uruchomienie python server.py:
Ruby… i Octopress
Zdecydowanie najwięcej kłopotów, ale to nie jest jakoś bardzo dziwne. Niemniej jednak udało mi sie uruchomić Octopress-aa, było to tak:
Instalacja rbenv i ruby-build, zdecydowałem się nie korzystać z wersji oferowanej przez “pact”.
if(/cygwin|mswin|mingw|bccwin|wince|emx/=~RUBY_PLATFORM)!=nilputs'## Set the codepage to 65001 for Windows machines'`chcp 65001`end
na:
1234
if(/cygwin|mswin|mingw|bccwin|wince|emx/=~RUBY_PLATFORM)!=nilputs'## Set the codepage to 65001 for Windows machines'`chcp.com 65001`end
Bez powyższego kroku miałem taki problem:
{ octopress } master » rake install
rake aborted!
Errno::ENOENT: No such file or directory - chcp 65001
/home/itoutline/octopress/Rakefile:32:in ``'
/home/itoutline/octopress/Rakefile:32:in `<top (required)>'
(See full trace by running task with --trace)
Wykonujemy rake install:
{ octopress } master » rake install
## Set the codepage to 65001 for Windows machines
## Copying classic theme into ./source and ./sass
mkdir -p source
cp -r .themes/classic/source/. source
mkdir -p sass
cp -r .themes/classic/sass/. sass
mkdir -p source/_posts
mkdir -p public
Następnie rake generate && rake preview:
{ octopress } master » rake generate && rake preview
## Set the codepage to 65001 for Windows machines
## Generating Site with Jekyll
directory source/stylesheets
write source/stylesheets/screen.css
Configuration file: /home/itoutline/octopress/_config.yml
Source: source
Destination: public
Generating...
done.
Auto-regeneration: disabled. Use --watch to enable.
## Set the codepage to 65001 for Windows machines
Starting to watch source with Jekyll and Compass. Starting Rack on port 4000
[2014-12-29 15:22:08] INFO WEBrick 1.3.1
[2014-12-29 15:22:08] INFO ruby 1.9.3 (2014-11-13) [i386-cygwin]
[2014-12-29 15:22:08] WARN TCPServer Error: Bad file descriptor - listen(2)
[2014-12-29 15:22:08] INFO WEBrick::HTTPServer#start: pid=4924 port=4000
>>> Compass is watching for changes. Press Ctrl-C to Stop.
Configuration file: /home/itoutline/octopress/_config.yml
write public/stylesheets/screen.css
Source: source
Destination: public
Generating...
done.
Mamy bloga:
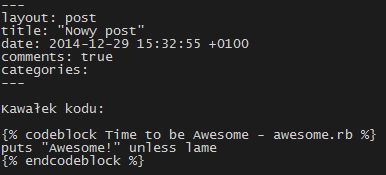
Ale to nie wszystko, próba umieszczenia takiego wpisu:
na blogu, zakończy się tak:
{ octopress } master » rake generate && rake preview
## Set the codepage to 65001 for Windows machines
## Generating Site with Jekyll
write source/stylesheets/screen.css
Configuration file: /home/itoutline/octopress/_config.yml
Source: source
Destination: public
Generating...
Liquid Exception: No such file or directory - C:\Windows\system32\cmd.exe in _posts/2014-12-29-nowy-post.markdown/#excerpt
done.
Auto-regeneration: disabled. Use --watch to enable.
## Set the codepage to 65001 for Windows machines
Starting to watch source with Jekyll and Compass. Starting Rack on port 4000
[2014-12-29 15:35:49] INFO WEBrick 1.3.1
[2014-12-29 15:35:49] INFO ruby 1.9.3 (2014-11-13) [i386-cygwin]
[2014-12-29 15:35:49] WARN TCPServer Error: Bad file descriptor - listen(2)
[2014-12-29 15:35:49] INFO WEBrick::HTTPServer#start: pid=7540 port=4000
Ostatni drobny kłopot to narzekanie na brak “python2” podczas generowania bloga:
which: no python2 in (/home/itoutline/.rbenv/versions/1.9.3-p551/lib/ruby/gems/1.9.1/bin:/home/itoutline/.rbenv/versions/1.9.3-p551/bin:/home/itoutline/.rbenv/libexec:/home/itoutline/.rbenv/plugins/ruby-build/bin:/home/itoutline/.rbenv/shims:/home/itoutline/.rbenv/bin:/home/itoutline/bin:/usr/local/bin:/usr/bin:/cygdrive/c/ProgramData/Oracle/Java/javap~...
Wystarczy utworzenie linku symbolicznego:
cd /usr/bin
ln -s python2.7.exe python2
“Chyba” wszystko działa:
Przed podsumowaniem
Czasami po uruchomieniu Babun-a może się pojawić coś takiego:
compdef: unknown command or service: git
compdef: unknown command or service: git
compdef: unknown command or service: git
compdef: unknown command or service: git
compdef: unknown command or service: git
compdef: unknown command or service: git
compdef: unknown command or service: git
{ ~ } »
Nie jest tak, że to tylko u mnie. Rozwiązanie w postaci:
compinit
cp .zcompdump .zcompdump-$HOSTNAME-5.0.2
rzeczywiście działa.
Podsumowując
Fajnie, że jest Cygwin, że powstał Babun ale chyba zdecydowanie lepiej jest po prostu uruchomić wirtualną maszynę na Virtualboxie. Chyba, że mamy ograniczone zasoby sprzętowe, nie mamy uprawnień, lubimy “grzebać” albo potrzebujemy dostępu tylko do podstawowych narzędzi Linux/GNU. Jeśli chodzi o to ostatnie to Cygwin/Babun zdecydowanie wygrywa z wirtualną maszyną.